Techniki, strategie i receptury budowy nowoczesnych aplikacji web przez wiele zespołów, które mogą dostarczać funkcjonalnosci niezależnie.
Czym są Micro Frontends?
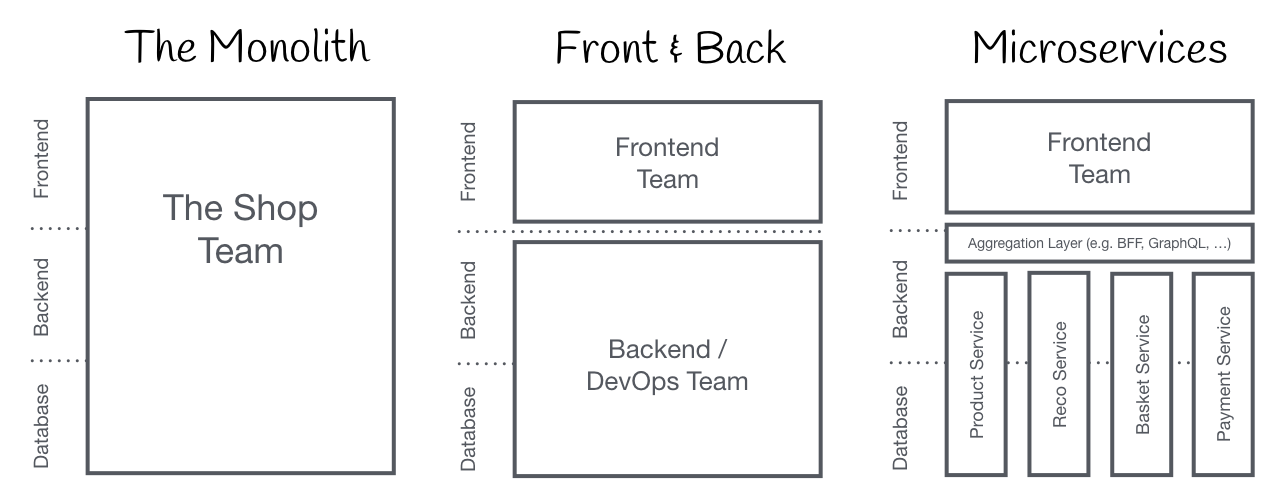
Termin Micro Frontends po raz pierwszy pojawił się w ThoughtWorks Technology Radar pod koniec 2016 roku. Rozszerza koncepcje mikrousług na świat frontendu. Zgodnie z obecnym trendem budujemy bogate w funkcje i wydajne aplikacje web, zwane również aplikacjami jednostronicowymi (SPA), które odwołuja się do mikrousług. Z biegiem czasu warstwa frontendowa, często rozwijana przez osobny zespół, rozrasta się i staje się trudniejsza w utrzymaniu. Nazywamy to monolitem frontendowym.
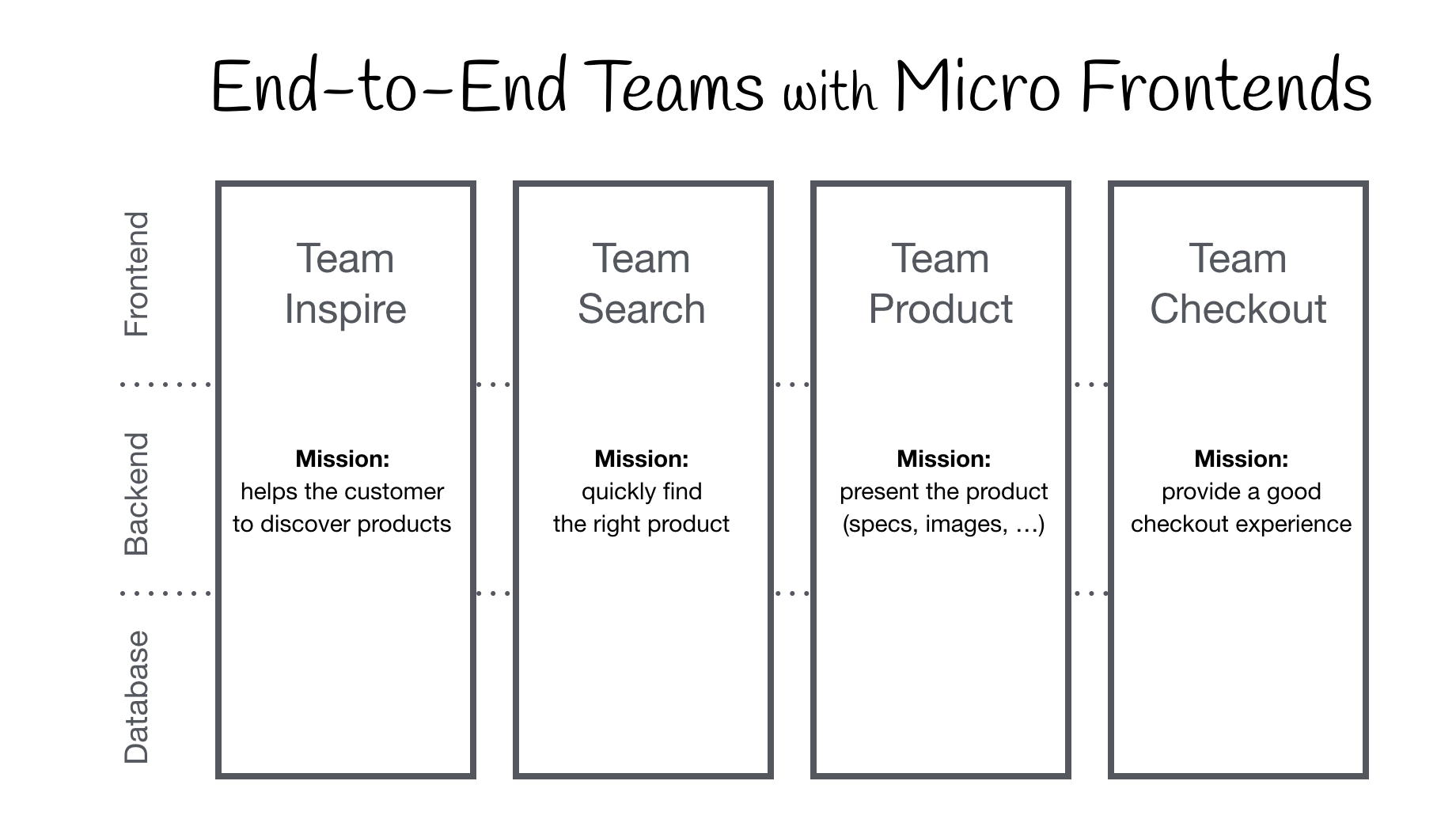
Ideą Micro Frontends jest myślenie o aplikacji web jako o kompozycji funkcjonalności, które są własnością niezależnych zespołów. Każdy zespół ma odrębną dziedzinę działalności lub misję, o którą się troszczy i w której się specjalizuje. Zespół jest interdyscyplinarny i rozwija swoje funkcje od początku do końca, od bazy danych po interfejs użytkownika.
Pomysł ten nie jest jednak nowy. Ma wiele wspólnego z koncepcją Self-contained Systems. W przeszłości takie podejście nosiło nazwę Frontend Integration for Verticalised Systems. Micro Frontends jest dużo bardziej przyjaznym i poręcznym terminem.
Monolithic Frontends
Organisation in Verticals
Czym jest nowoczesna aplikacja web?
We wstępie użyłem sformułowania „budowa nowoczesnych aplikacji web”. Zdefiniujmy założenia, które wiążą się z tym terminem.
Aby spojrzeć na to z szerszej perspektywy, Aral Balkan napisał post na blogu o tym, co nazywa Documents‐to‐Applications Continuum. Wymyśla koncepcję osi, w której witryna zbudowana ze statycznych dokumentów połączonych linkami znajduje się po lewej stronie, a w pełni zorientowana na zachowania, aplikacja bez treści, jak internetowy edytor zdjęć, znajduje się po prawej.
Jeśli umieścisz swój projekt po lewej stronie tego spektrum, dobrym wyborem będzie integracja na poziomie serwera WWW. W tym modelu serwer zbiera i łączy ciągi znaków HTML ze wszystkich komponentów składających się na żądaną przez użytkownika stronę. Aktualizacje odbywają się poprzez przeładowanie strony z serwera lub wymianę jej części przez ajax. Gustaf Nilsson Kotte napisał obszerny artykuł na ten temat.
Gdy interfejs użytkownika musi zapewniać natychmiastową informację zwrotną, nawet w przypadku zawodnych połączeń, witryna renderowana wyłącznie przez serwer nie będzie już wystarczająca. Chcąc wdrożyć techniki, takie jak Optimistic UI lub Skeleton Screens musisz mieć możliwość aktualizacji swojego interfejsu użytkownika na samym urządzeniu. Termin Google Progressive Web Apps trafnie opisuje balansowanie pomiędzy byciem dobrym obywatelem sieci (progresywne ulepszanie), a jednocześnie zapewnieniem wydajnosci podobnej do aplikacji. Ten rodzaj aplikacji znajduje się gdzieś mniej więcej po środku kontinuum witryna-aplikacja. Tutaj rozwiązanie oparte wyłącznie na serwerze nie jest już wystarczające i musimy przenieść integrację do przeglądarki. To właśnie jest tematem niniejszego artykułu.
Podstawowe idee kryjące się za Micro Frontends
- Bądź niezależny od technologii
Każdy zespół powinien mieć możliwość wyboru i ulepszenia swojego stosu bez konieczności koordynacji z innymi zespołami. Custom Elements to świetny sposób na ukrycie szczegółów implementacji, zapewniając jednocześnie neutralny interfejs innym. - Izoluj kod zespołu
Nie udostępniaj środowiska uruchomieniowego, nawet jeśli wszystkie zespoły używają tego samego frameworka. Twórz niezależne aplikacje, które są samowystarczalne. Nie polegaj na wspólnych stanach ani zmiennych globalnych. - Ustal prefiksy zespołów
Uzgodnij konwencje nazewnictwa tam, gdzie izolacja nie jest jeszcze możliwa. Użyj przestrzeni nazw dla CSS, zdarzeń, Local Storage i ciastek w celu uniknięcia kolizji i pokazania własności. - Preferuj natywne funkcje przeglądarki zamiast niestandardowych API
Używaj Zdarzeń przeglądarki do komunikacji zamiast budować globalny system PubSub. Jeśli naprawdę musisz zbudować międzyzespołowe API, postaraj się, aby było to jak najprostsze. - Zbuduj elastyczną witrynę
Twoja funkcja powinna być użyteczna, nawet jeśli JavaScript nie zadziałał lub nie został jeszcze uruchomiony. Użyj Universal Rendering i Progressive Enhancement, aby poprawić postrzeganą wydajność.
DOM jest API
Custom Elements, czyli aspekt interoperacyjności ze specyfikacji Web Components, jest dobrą podstawą do integracji w przeglądarce. Każdy zespół buduje swój komponent przy użyciu wybranej przez siebie technologii i opakowuje go w Custom Element (np. <order-minicart></order-minicart>). Specyfikacja DOM tego konkretnego elementu (nazwa tagu, atrybuty i zdarzenia) działa jak kontrakt lub publiczne API dla innych zespołów. Zaletą jest to, że mogą korzystać z komponentu i jego funkcjonalności bez znajomości implementacji. Muszą jedynie mieć możliwość interakcji z DOM.
Jednak same Custom Elements nie są rozwiązaniem dla wszystkich naszych potrzeb. Aby mówić o progresywnym ulepszaniu, uniwersalnym renderowaniu czy routingu, potrzebujemy dodatkowego oprogramowania.
Ta strona jest podzielona na dwa główne obszary. Najpierw omówimy Kompozycję strony — jak złożyć stronę z komponentów należących do różnych zespołów. Następnie pokażemy przykłady implementacji przejść pomiędzy stronami po stronie klienta.
Kompozycja strony
Poza samą integracją kodu po stronie klienta i serwera napianego w różnych frameworkach, istnieje wiele pobocznych tematów, które należy omówić: mechanizmy izolowania js, unikanie konfliktów css, ładowanie zasobów w razie potrzeby, dzielenie wspólnych zasobów między zespołami, pobieranie danych i dobrej prezentacji wskaźników ładowania dla użytkownika. Zajmiemy się tymi tematami krok po kroku.
Prototyp
Jako podstawa dla poniższych przykładów posłuży nam strona produktu sklepu z traktorami.
Na stronie jest selektor modelu do przełączania między trzema różnymi modelami traktorów. Po zmianie obraz produktu, aktualizowane są nazwa, cena i rekomendacje. Dostępny jest również przycisk kupowania, który dodaje wybrany model do koszyka, a minikoszyk u góry odpowiednio się aktualizuje.
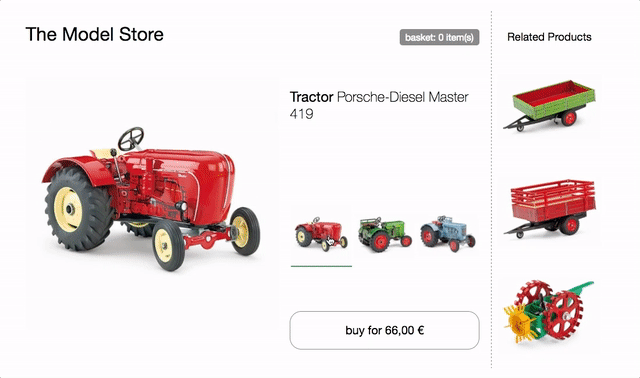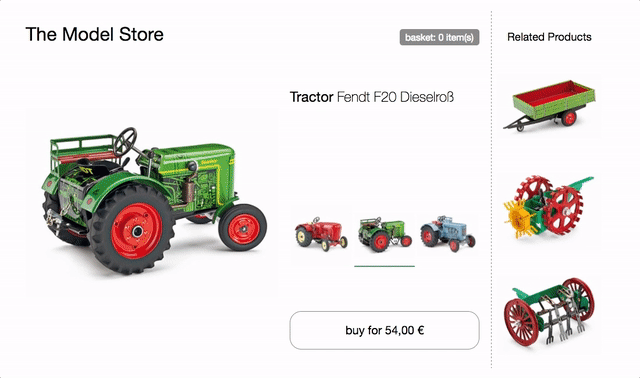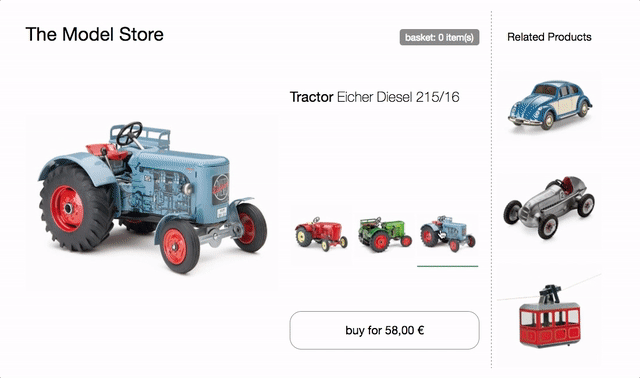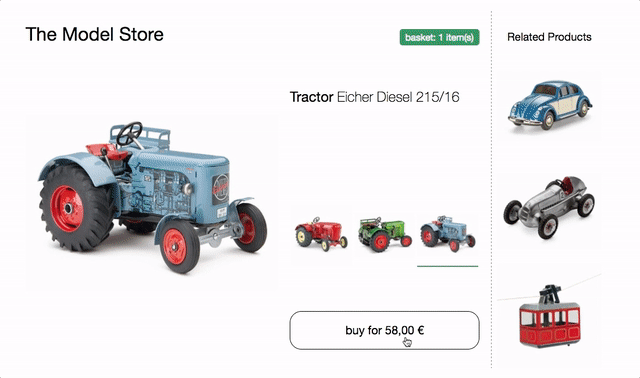
spróbuj w przeglądarce i sprawdź kod
Cały HTML jest generowany po stronie klienta przy użyciu zwykłego JavaScript i szablonów ES6 z bez zależności. Kod wykorzystuje prostą separację stanu/znaczników i ponownie renderuje całą stronę klienta HTML po każdej zmianie - na razie bez fantazyjnego różnicowania DOM i bez uniwersalnego renderowania. Nie ma też separacji zespołu - kod jest zapisany w jednym pliku js/css.
Integracja po stronie klienta
W tym przykładzie strona jest podzielona na osobne komponenty/fragmenty należące do trzech zespołów. Team Checkout (niebieski) jest teraz odpowiedzialny za wszystko, co dotyczy procesu zakupu, a mianowicie za przycisk kupowania i minikoszyk. Team Inspire (zielony) zarządza rekomendacjami produktów na tej stronie. Sama strona jest własnością Team Product (czerwony).
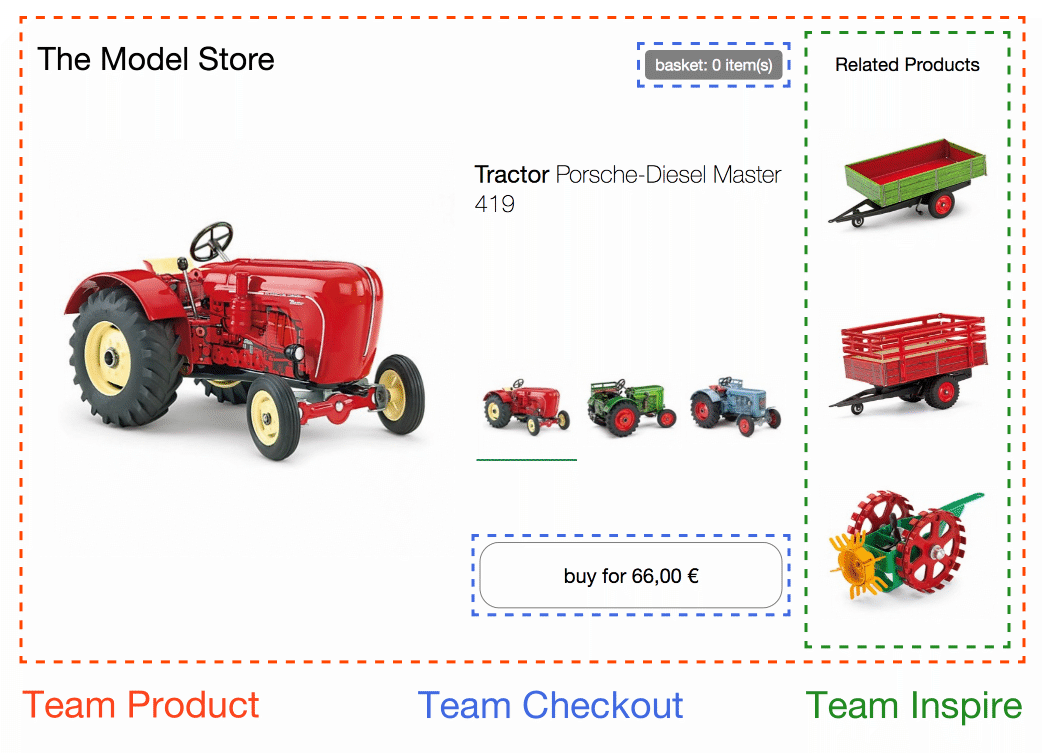
spróbuj w przeglądarce i sprawdź kod
Każdy zespół
Team Product decyduje, która funkcjonalność jest uwzględniona i gdzie jest umieszczona na stronie. Strona zawiera informacje, które może dostarczyć sam Team Product, takie jak nazwa produktu, zdjęcie i dostępne modele. Może jednak zawierać również fragmenty (Custom Elements) z innych zespołów.
Jak stworzyć Custom Element?
Weźmy jako przykład przycisk kupowania. Team Product wstawił przycisk po prostu dodając w żądanym miejscu strony <blue-buy sku="t_porsche"></blue-buy>. Aby to zadziałało, Team Checkout musiał zarejestrować element blue-buy na stronie.
class BlueBuy extends HTMLElement {
connectedCallback() {
this.innerHTML = `<button type="button">buy for 66,00 €</button>`;
}
disconnectedCallback() { ... }
}
window.customElements.define('blue-buy', BlueBuy);
Teraz za każdym razem, gdy przeglądarka napotyka nowy tag blue-buy, wywoływane jest connectedCallback. this jest odniesieniem do głównego węzła DOM Custom Element. Dostępne są wszystkie właściwości i metody standardowego elementu DOM, takich jak innerHTML lub getAttribute().

Podczas nazywania elementu jedynym wymaganiem, jakie określa specyfikacja, jest to, że nazwa musi zawierać myślnik (-), aby zachować zgodność z nadchodzącymi nowymi tagami HTML. W kolejnych przykładach używana jest konwencja nazewnictwa [kolor_zespołu]-[funkcja]. Przestrzeń nazw zespołu chroni przed kolizjami a zarazem zespół będący właścicielem funkcji staje się oczywisty, z samego spojrzenia na DOM.
Komunikacja rodzic-dziecko / Modyfikacja DOM
Gdy użytkownik wybierze inny ciągnik w selektorze modeli, przycisk kupowania musi zostać odpowiednio zaktualizowany. Aby osiągnąć ten produkt zespołowy, wystarczy usunąć istniejący element z DOM i wstawić nowy.
container.innerHTML;
// => <blue-buy sku="t_porsche">...</blue-buy>
container.innerHTML = '<blue-buy sku="t_fendt"></blue-buy>';
Funkcja disconnectedCallback starego elementu jest wywoływana synchronicznie, aby zapewnić elementowi szansę na porządki, takie jak wyczyszczenie podpiętych zdarzeń. Następnie wywoływana jest funkcja connectedCallback nowo utworzonego elementu t_fendt.
Inną, bardziej wydajną opcją jest po prostu aktualizacja atrybutu sku istniejącego elementu.
document.querySelector('blue-buy').setAttribute('sku', 't_fendt');
Gdyby Team Product używał silnika szablonów, który obsługuje różnicowanie DOM, takiego jak React, algorytm zrobiłby to automatycznie.

Aby to obsłużyć Custom Element może zaimplementować funkcję attributeChangedCallback i określić listę observedAttributes, dla których ma zostać wywołana ta funkcja.
const prices = {
t_porsche: '66,00 €',
t_fendt: '54,00 €',
t_eicher: '58,00 €',
};
class BlueBuy extends HTMLElement {
static get observedAttributes() {
return ['sku'];
}
connectedCallback() {
this.render();
}
render() {
const sku = this.getAttribute('sku');
const price = prices[sku];
this.innerHTML = `<button type="button">buy for ${price}</button>`;
}
attributeChangedCallback(attr, oldValue, newValue) {
this.render();
}
disconnectedCallback() {...}
}
window.customElements.define('blue-buy', BlueBuy);
Aby uniknąć powielania kodu, wprowadzono metodę render(), która jest wywoływana z connectedCallback i attributeChangedCallback. Ta metoda zbiera potrzebne dane i ustawia zawartość innerHTML nowego znacznika. Decydując się na bardziej wyrafinowany silnik szablonów lub framework wewnątrz Custom Element, tutaj trafiłby jego kod inicjujący.
Wsparcie w przeglądarkach
W powyższym przykładzie zastosowano specyfikację Custom Element V1, która jest obecnie obsługiwana w przeglądarkach Chrome, Safari i Opera. Ale z document-register-element dostępny jako lekki i przetestowany w boju polyfill, zadziała we wszystkich przeglądarkach. Korzysta on z powszechnie wspieranego Mutation Observer API, więc w tle nie ma podglądania drzewa DOM.
Kompatybilność frameworków
Ponieważ Custom Elements są standardem web, obsługują je wszystkie główne frameworki JavaScript, takie jak Angular, React, Preact, Vue czy Hyperapp. Ale kiedy przejdziesz do szczegółów, nadal istnieje kilka problemów z implementacją w niektórych frameworkach. W Custom Elements Everywhere Rob Dodson przygotował zestaw testów zgodności, który zwraca uwagę na nierozwiązane problemy.
Unikaj anarchii frameworków
Korzystanie z elementów niestandardowych to świetny sposób na osiągnięcie wysokiego stopnia rozdzielenia między fragmentami poszczególnych zespołów. W ten sposób każdy zespół ma swobodę wyboru frameworka frontendowego. Ale to, że możesz, nie oznacza, że mieszanie różnych technologii jest dobrym pomysłem. Staraj się unikać Micro Frontends Anarchy i stwórz rozsądny poziom zgodności między różnymi zespołami. W ten sposób zespoły mogą dzielić się wiedzą i najlepszymi praktykami. Ułatwi Ci to również życie, gdy zechcesz założyć centralną bibliotekę wzorów. To powiedziawszy, możliwość łączenia technologii może być przydatna, gdy pracujesz ze starszą aplikacją i chcesz przeprowadzić migrację do nowego stosu technologicznego.
Komunikacja między dzieckiem a rodzicem lub rodzeństwem / Zdarzenia DOM
Przekazywanie w dół atrybutów nie jest wystarczające dla wszystkich interakcji. W naszym przykładzie minikoszyk powinien się odświeżyć, gdy użytkownik kliknie przycisk kupowania.
Oba fragmenty są własnością Team Checkout (niebieski), więc mogliby zbudować coś w rodzaju wewnętrznego API JavaScript, które poinformuje minikoszyk, kiedy naciśnięto przycisk. Wymagałoby to jednak wzajemnej znajomości instancji komponentów, a także stanowiłoby naruszenie izolacji.
Czystszym sposobem jest użycie mechanizmu PubSub, w którym komponent może publikować wiadomość, a inne komponenty mogą subskrybować określone tematy. Na szczęście przeglądarki mają tę funkcję wbudowaną. Dokładnie w ten sposób działają zdarzenia przeglądarki, takie jak click, select lub mouseover. Oprócz natywnych zdarzeń istnieje również możliwość tworzenia zdarzeń wyższego poziomu za pomocą new CustomEvent(...). Zdarzenia są zawsze powiązane z węzłem DOM, w którym zostały utworzone/wysłane. Większość natywnych zdarzeń obsługuje bąbelkowanie. Umożliwia to nasłuchiwanie wszystkich zdarzeń w określonym poddrzewie DOM. Jeśli chcesz nasłuchiwać wszystkich zdarzeń na stronie, dołącz obsługę zdarzenia do elementu okna. Oto przykład tworzenia zdarzenia blue:basket:changed:
class BlueBuy extends HTMLElement {
[...]
connectedCallback() {
[...]
this.render();
this.firstChild.addEventListener('click', this.addToCart);
}
addToCart() {
// maybe talk to an api
this.dispatchEvent(new CustomEvent('blue:basket:changed', {
bubbles: true,
}));
}
render() {
this.innerHTML = `<button type="button">buy</button>`;
}
disconnectedCallback() {
this.firstChild.removeEventListener('click', this.addToCart);
}
}
Minikoszyk może teraz subskrybować to zdarzenie na elemencie window i otrzymywać powiadomienia, kiedy powinien odświeżyć swoje dane.
class BlueBasket extends HTMLElement {
connectedCallback() {
[...]
window.addEventListener('blue:basket:changed', this.refresh);
}
refresh() {
// fetch new data and render it
}
disconnectedCallback() {
window.removeEventListener('blue:basket:changed', this.refresh);
}
}
Przy takim podejściu fragment minikoszyka dodaje obsługę zdarzenia do elementu DOM, który jest poza jego zakresem (window). Powinno to być bezpieczne w przypadku wielu aplikacji, ale jeśli nie czujesz się z tym komfortowo, możesz zawsze zastosować podejście, w którym sama strona (Team Product) nasłuchuje zdarzenia i powiadamia minikoszyk, wywołując funkcję refresh() na elemencie DOM.
// page.js
const $ = document.getElementsByTagName;
$('blue-buy')[0].addEventListener('blue:basket:changed', function() {
$('blue-basket')[0].refresh();
});
Imperatywne wywoływanie metod DOM jest dość rzadkie, ale można je znaleźć na przykład w video element api. Jeśli to możliwe, należy preferować podejście deklaratywne (zmiana atrybutu).
Renderowanie po stronie serwera / Renderowanie uniwersalne
Custom Elements świetnie nadają się do integracji komponentów w przeglądarce. Jednak podczas tworzenia witryny, która jest dostępna w sieci, Ważna jest wydajność. Istnieje duże prawdopodobieństwo, że dopóki wszystkie frameworki js nie zostaną pobrane i uruchomione użytkownicy będą widzieć biały ekran. Dodatkowo dobrze jest pomyśleć o tym, co stanie się z witryną, jeśli JavaScript zawiedzie lub zostanie zablokowany. Wagę tego problemu pokazuje Jeremy Keith w swoim ebooku/podcaście Resilient Web Design. Dlatego możliwość wyrenderowania podstawowej zawartości na serwerze jest kluczowa. Niestety specyfikacja komponentów web w ogóle nie mówi o renderowaniu po stronie serwera. Nie ma JavaScript, nie ma Custom Elements :(
Custom Elements + Server Side Includes = ❤️
W celu uruchomienia renderowania po stronie serwera zrefaktorujemy poprzedni przykład. Każdy zespół ma własny serwer ekspresowy, a metoda render() Custom Element jest również dostępna za pośrednictwem adresu URL.
$ curl http://127.0.0.1:3000/blue-buy?sku=t_porsche
<button type="button">buy for 66,00 €</button>
Nazwa znacznika Custom Element jest używana jako fragment ścieżki - atrybuty stają się parametrami zapytania. Teraz istnieje sposób na renderowanie zawartości każdego komponentu po stronie serwera. W połączeniu z <blue-buy>-Custom Element osiągamy coś, co jest dość bliskie do Universal Web Component:
<blue-buy sku="t_porsche">
<!--#include virtual="/blue-buy?sku=t_porsche" -->
</blue-buy>
Komentarz #include jest częścią Server Side Includes, która jest funkcją dostępną na większości serwerów WWW. Tak, jest to ta sama technika, której używano kiedyś do umieszczania bieżącej daty na stronach. Istnieje również kilka alternatywnych technik, takich jak ESI, nodesi, compoxure i tailor, ale w naszych projektach SSI sprawdziło się jako proste i niezwykle stabilne rozwiązanie.
Komentarz #include jest zastępowany odpowiedzią /blue-buy?sku=t_porsche zanim serwer WWW wyśle całą stronę do przeglądarki. Konfiguracja w nginx wygląda tak:
upstream team_blue {
server team_blue:3001;
}
upstream team_green {
server team_green:3002;
}
upstream team_red {
server team_red:3003;
}
server {
listen 3000;
ssi on;
location /blue {
proxy_pass http://team_blue;
}
location /green {
proxy_pass http://team_green;
}
location /red {
proxy_pass http://team_red;
}
location / {
proxy_pass http://team_red;
}
}
Dyrektywa ssi: on; włącza funkcję SSI, a bloki upstream i location dla każdego zespołu mają zapewnić, że wszystkie adresy URL zostanąskierowane do właściwej aplikacji (np. /blue do team_blue: 3001). Dodatkowo trasa / jest mapowana do zespołu red, który kontroluje stronę główną/stronę produktu.
Poniższa animacja przedstawia sklep z traktorami w przeglądarce z wyłączoną obsługą JavaScript.
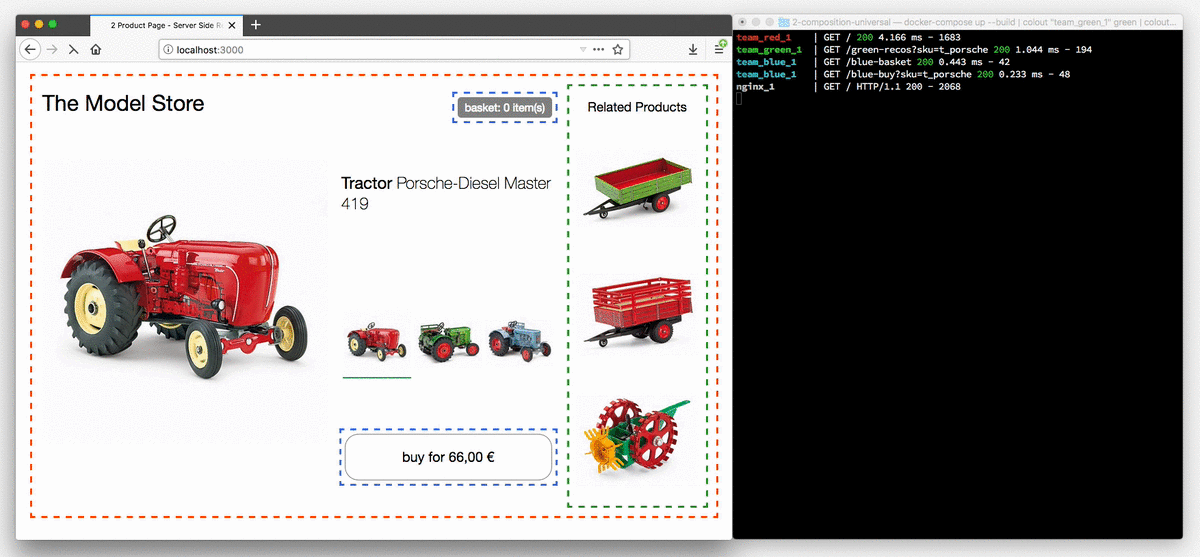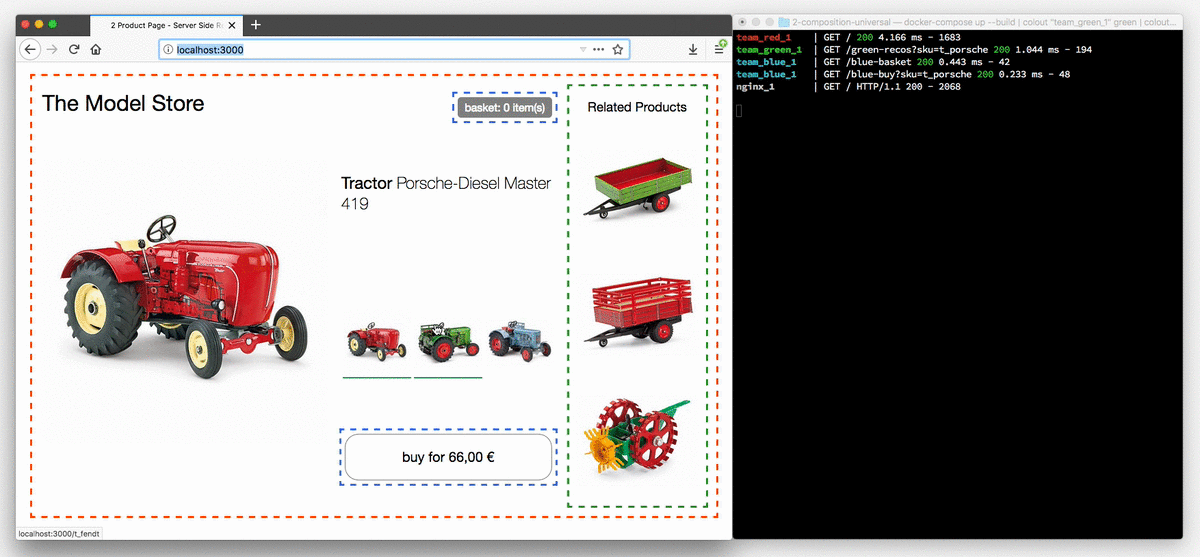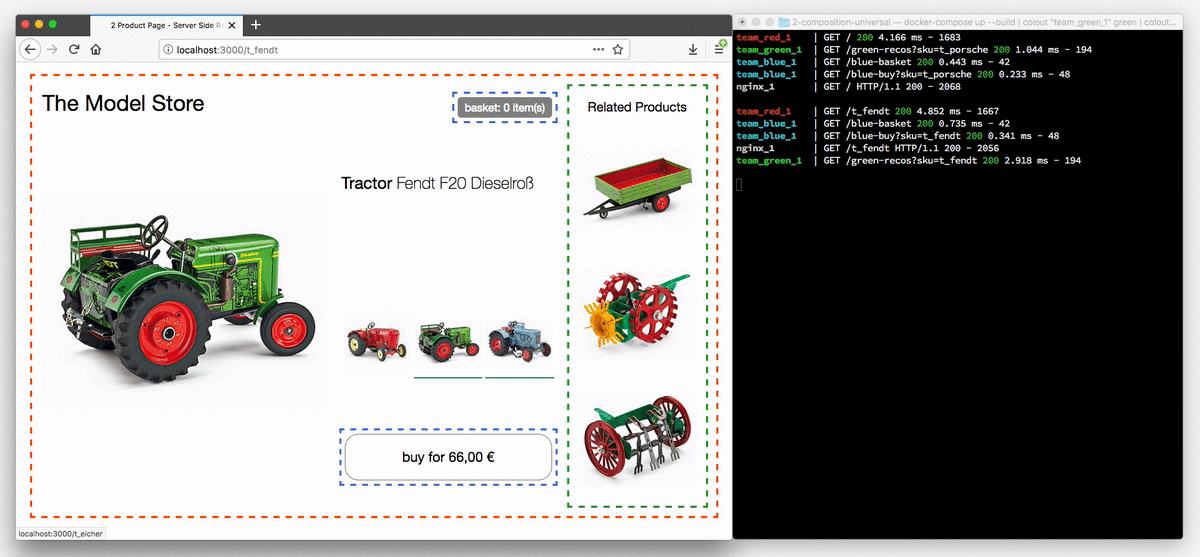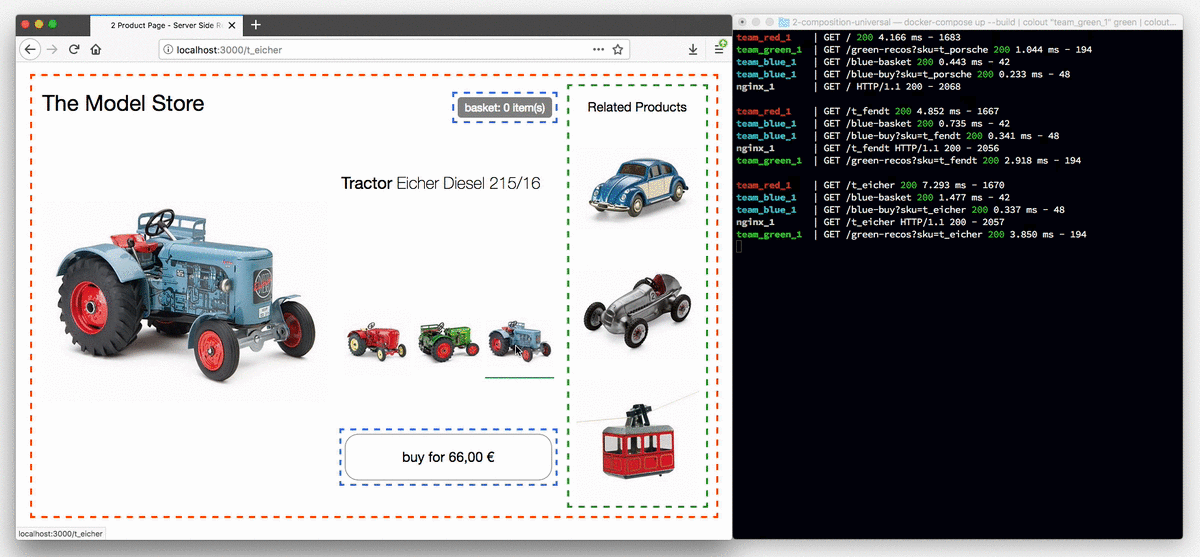
Przyciski wyboru modelu są teraz rzeczywistymi linkami, a każde kliknięcie powoduje przeładowanie strony. Terminal po prawej ilustruje proces routowania zapytania o stronę do zespołu red, który kontroluje stronę produktową, po czym strona jest uzupełniana fragmentami z zespołu blue i green.
Po ponownym włączeniu JavaScript widoczne będą tylko komunikaty dziennika serwera dotyczące pierwszego żądania. Wszystkie kolejne zmiany ciągnika są obsługiwane po stronie klienta, tak jak w pierwszym przykładzie. W późniejszym przykładzie dane produktu zostaną wyodrębnione z kodu JavaScript i w razie potrzeby załadowane przez żądanie REST.
Możesz poeksperymentować z kodem tego przykładu na komputerze lokalnym. Musisz jedynie zainstalować Docker Compose.
git clone https://github.com/neuland/micro-frontends.git
cd micro-frontends/2-composition-universal
docker-compose up --build
Następnie Docker uruchamia nginx na porcie 3000 i buduje obraz node.js dla każdego zespołu. Kiedy otworzysz http://127.0.0.1:3000/ w przeglądarce, powinieneś zobaczyć czerwony traktor. Połączony dziennik docker-compose ułatwia sprawdzenie, co dzieje się w sieci. Niestety nie ma możliwości kontrolowania koloru wyjściowego, więc musisz znieść fakt, że niebieski zespół może być podświetlony na zielono :)
Pliki src są mapowane do poszczególnych kontenerów, a aplikacja węzła przeładuje się po wprowadzeniu zmiany w kodzie. Zmiana nginx.conf wymaga restartu docker-compose, aby odniosła skutek. Więc nie krępuj się bawić i wyrażać opinię.
Ładowanie danych i stany pobierania
Wadą podejścia SSI/ESI jest to, że najwolniejszy fragment określa czas ładowania całej strony.
Dobrze zatem, gdy odpowiedź fragmentu może być buforowana.
W przypadku fragmentów, które są kosztowne w renderowaniu i trudne do buforowania, często dobrym pomysłem jest wykluczenie ich z początkowego renderowania.
Mogą być ładowane asynchronicznie w przeglądarce.
W naszym przykładzie fragment green-recos, który pokazuje spersonalizowane rekomendacje jest do tego dobrym kandydatem.
Jednym z możliwych rozwiązań byłoby po prostu pominięcie SSI Include przez zespół czerwony.
Before
<green-recos sku="t_porsche">
<!--#include virtual="/green-recos?sku=t_porsche" -->
</green-recos>
After
<green-recos sku="t_porsche"></green-recos>
Ważna uwaga dodatkowa: Custom Elements nie mogą być samozamykające się, więc zapis <green-recos sku="t_porsche" /> nie zadziałałby poprawnie.

Renderowanie odbywa się tylko w przeglądarce. Jednak, jak widać na animacji, zmiana ta wprowadziła widoczne ponowne formatowanie strony. Obszar poleceń jest początkowo pusty. JavaScript zespołu zielonego jest ładowany i wykonywany. Wykonywane jest żadanie API w celu pobrania spersonalizowanej rekomendacji. Rekomendowany znacznik jest renderowany i pobierane są skojarzone obrazy. Fragment potrzebuje teraz więcej miejsca i rozpycha układ strony.
Istnieją różne opcje, aby uniknąć takiego irytującego rozpychania. Zespół czerwony, który kontroluje stronę, mógłby ustalić wysokość kontenera rekomendacji. Na responsywnej stronie często jednak trudno jest określić wysokość, ponieważ może się różnić dla różnych rozmiarów ekranu. Większym problemem jest jednak to, że taki rodzaj porozumienia między zespołami tworzy ścisłe powiązanie między czerwonymi i zielonymi. Jeśli zespół zielonych chce wprowadzić dodatkowy nagłówek w elemencie rekomendacji, to musi się dogadać z zespołem czerwonych w kwestii nowej wysokości. Oba zespoły musiałyby wprowadzić swoje zmiany jednocześnie, aby uniknąć zepsucia układu.
Lepszym sposobem jest użycie techniki o nazwie Skeleton Screens.
Zespół czerwony pozostawia SSI green-recos w szablonie.
Zespół zielony zmienia metodę renderowania po stronie serwera swojego fragmentu, tak aby tworzył schematyczną wersję zawartości.
znaczniki szkieletu mogą ponownie wykorzystywać części stylów układu rzeczywistej treści.
W ten sposób rezerwuje potrzebną przestrzeń, a załadowanie właściwej treści nie prowadzi do przeskoku.

Szkieletowe ekrany są również bardzo przydatne do renderowania po stronie klienta. Kiedy Twój niestandardowy element zostanie wstawiony do DOM w wyniku działania użytkownika, może natychmiast renderować szkielet, dopóki nie dotrą dane, których potrzebuje z serwera.
Nawet przy zmianie atrybutu, jak w przypadku wyboru modelu, możesz chcieć przełączyć się na widok szkieletu, dopóki nie pojawią się nowe dane. W ten sposób użytkownik otrzymuje wskazówkę, że coś się dzieje we fragmencie. Jednak gdy serwer reaguje szybko, krótkie szkieletowe migotanie między starymi a nowymi danymi również może być irytujące. Pomocne może być zachowanie starych danych lub użycie inteligentnych limitów czasu. Więc używaj tej techniki rozsądnie i staraj się uzyskać opinie użytkowników.
Nawigacja pomiędzy stronami
ciąg dalszy nastąpi wkrótce … (obiecuję)
obejrzyj Github Repo, aby otrzymać powiadomienie
Dodatkowe zasoby
- Książka: Micro Frontends in Action Napisane przeze mnie.
- Dyskusja: Micro Frontends - MicroCPH, Copenhagen 2019 (Slajdy) The Nitty Gritty Details or Frontend, Backend, 🌈 Happyend
- Dyskusja: Micro Frontends - Web Rebels, Oslo 2018 (Slajdy) Think Smaller, Avoid the Monolith, ❤️the Backend
- Slajdy: Micro Frontends - JSUnconf.eu 2017
- Talk: Break Up With Your Frontend Monolith - JS Kongress 2017 Elisabeth Engel talks about implementing Micro Frontends at gutefrage.net
- Artykuł: Micro Frontends Artykuł Cama Jacksona na blogu Martina Fowlersa
- Post: Micro frontends - a microservice approach to front-end web development Tom Söderlund wyjaśnia podstawową koncepcję i podaje linki na ten temat
- Post: Microservices to Micro-Frontends Sandeep Jain podsumowuje kluczowe zasady stojące za mikroserwisami i micro frontends
- Zbiór linków: Micro Frontends by Elisabeth Engel obszerna lista postów, wykładów, narzędzi i innych zasobów na ten temat
- Awesome Micro Frontends wyselekcjonowana lista linków autorstwa Christiana Ulbricha 🕶
- Custom Elements Everywhere Upewnij się, że różne frameworki i Custom Elements mogą być najlepszymi przyjaciółmi
- Ciągniki można kupić na manufactum.com :)
Ten sklep jest rozwijany przez dwa zespoły przy użyciu opisanych tutaj technik.
Powiązane techniki
– Posty: Cookie Cutter Scaling David Hammet napisał serię postów na blogu na ten temat.
- Wikipedia: Java Portlet Specification Specyfikacja omawiająca podobne tematy podczas tworzenia portali korporacyjnych.
Rzeczy, które nadejdą … (wkrótce)
- Przypadki użycia
- Nawigacja pomiędzy stronami
- miękka vs. twarda nawigacja
- router uniwersalny
- …
- Nawigacja pomiędzy stronami
- Tematy poboczne
- Izolowany CSS / spójny interfejs użytkownika / przewodniki po stylach i bibliotekach wzorców
- Wydajność przy początkowym ładowaniu
- Wydajność podczas korzystania z witryny
- Ładowanie CSS’a
- Ładowanie JS
- Testy integracyjne
- …
Contributors
- Koike Takayuki, który przetłumaczył stronę na japoński.
- Jorge Beltrán, który przetłumaczył stronę na hiszpański.
- Bruno Carneiro, który przetłumaczył stronę na portugalski.
- Soobin Bak, który przetłumaczył stronę na koreański.
- Sergei Babin, który przetłumaczył stronę na rosyjski.
- Shiwei Yang, który przetłumaczył stronę na chiński.
- Riccardo Moschetti, który przetłumaczył stronę na włoski.
- Dominik Czechowski, który przetłumaczył stronę na polski.
Ta strona jest generowana przez Github Pages. Jego źródło można znaleźć pod adresem neuland/micro-frontends.